스프링 mvc 강의 1편의 마지막 쯤으로 가니까 타임리프를 활용한 프로젝트 구현이 진행됐다.
사실 기존에 만들던 캘린더 API는 프론트가 있다고 가정하고 만든 api 형태의 백엔드라, 타임리프를 사용할 이유가 없었다.
그런데 강의에서 백엔드 개발자더라도 SSR을 위해 타임리프로 화면 그리기 정도는 할 줄 알아야 한다라고 이야기했고,
또 간단한 어드민 페이지 정도는 프론트에 맡기는 거보단 직접 만드는게 편하다고 했기에
타임리프를 써서 간단한 어드민 페이지를 만들어봤다.
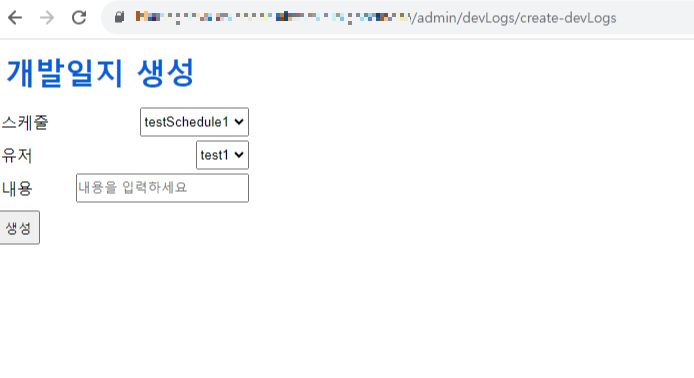
개발 일지 생성 화면이다.
스케줄과 개발일지 작성자를 선택한 후에 내용을 입력하면 된다.
(물론 이건 어드민 화면이므로 작성자와 스케줄을 직접 선택했지만,
실제 서비스에선 로그인 한 후에 스케줄에 댓글을 다는 식으로 개발일지를 남기려 했다.)
// Admin 컨트롤러
@Controller
@RequiredArgsConstructor
public class AdminDevLogController{
private final ScheduleService scheduleService;
private final UserService userService;
private final DevLogService devLogService;
// 개발일지 생성 화면
@GetMapping("/admin/devLogs/create-devLogs")
public String createDevLogForm(Model model){
Pageable pageable = PageRequest.of(0,20);
List<Schedule> scheduleList = scheduleService.findSchedules(pageable).getContent();
List<User> users = userService.findAllBySearch(pageable, null, null).getContent();
List<String> userList = users.stream()
.map(u -> u.getAccountId())
.collect(toList());
model.addAttribute("scheduleList", scheduleList);
model.addAttribute("userList", userList);
return "devLogs/devLogs-create-form";
}
// 개발일지 생성
@PostMapping("/admin/devLogs/create-devLogs")
public String createDevLog(CreateDevLogRequest request){
devLogService.createDevLog(request);
return "redirect:/admin/devLogs/read-devLogs";
}
}<!-- devLogs-create-form.html -->
<!DOCTYPE HTML>
<html xmlns: th=”http://www.thymeleaf.org”>
<head>
<title>BlazingDevs Calender!</title>
<link th:href="@{/css/create-form.css}" rel="stylesheet" />
</head>
<body>
<div class="title">
<h1>개발일지 생성</h1>
</div>
<div class="container">
<form role="form" action="/admin/devLogs/create-devLogs" method="post">
<div class="form-group">
<label>스케줄</label>
<select name="scheduleId">
<option th:each="schedule: ${scheduleList}" th:text="${schedule.name}" th:value="${schedule.id}"></option>
</select>
</div>
<div class="form-group">
<label>유저</label>
<select name="userAccountId">
<option th:each="user: ${userList}" th:text="${user}"></option>
</select>
</div>
<div class="form-group">
<label>내용</label>
<input type="text" name="content" class="form-control" placeholder="내용을 입력하세요"/>
</div>
<button type="submit" class="btn">생성</button>
</form>
</div>
</body>
</html>
mvc 강의 1편 마지막에서 간단히 배운 내용으로 직접 만들어 봤다.
- 타임리프 사용 선언 : <html xmls: th="http://www.thymeleaf.org">
- html 속성 변경 : th:바꿀 속성="${내용}", 이때 내용은 컨트롤러에서 model.addAttribute로 넘겨줄 수 있다.
- th:xxx 가 붙은 부분은 SSR로 서버가 실행될때 변경된다.
- th:each="xxx : ${xxxList}" 사용시 리스트로 받아온 값을 이용해 반복문을 사용할 수 있다.
- "${내용}" 과 같은 리터럴은 다른 문자열과 함께 사용할 수 없다. 무조건 따로 쓴 후 + 로 합쳐야한다.
- |...| 을 사용하면 리터럴을 대체해 사용할 수 있다. (<span th:text = “|Hello world ${username}|”>)
PRG 패턴
POST 방식으로 온 요청에 대해서 GET 방식의 웹페이지로 리다이렉트 시키는 패턴을 말한다.
Post 방식으로 온 요청을 사용한 후 비즈니스 로직(값 DB에 저장)을 진행한 다음 get 방식으로 html을 다시 반환하면
사용자가 뒤로가기,새로고침을 누를 시 방금 전의 post 요청이 계속해서 다시 발생한다.
따라서 redirect를 이용해 새로운 페이지로 이동을 시켜준다.
브라우저는 302 응답코드와 url을 받으며, 받은 url로 다시 한 번 get 요청을 보내고 이동시킨다.
이렇게 하면 비즈니스 로직이 중복 발생하지 않는다.
또 브라우저는 3XX 요청을 받은 페이지는 저장하지 않아서 뒤로 가기를 하더라도 요청 페이지가 다시 나오지 않는다.
어드민 페이지를 만들면서 느낀 점
1. 프론트 화면을 만들면 생각보다 신경써야할 내용들이 많다.
뒤로가기 구현, 메인 화면으로 돌아가기 구현 등의 프론트가 신경써야할 부분 뿐만 아니라
회원가입 시 ID 중복 체크, 유저 추가 시 중복 방지와 같은 백엔드 api에선 단순히 오류만 보내고 끝냈는데
화면을 구현하면 더 신경써야 할 로직들이 많았다.
2. Contoller 를 새로 만들면서 느낀 점
왜 service 계층이 dto에 의존하지 않는 것이 좋은지 잘 알겠다.
admin 페이지를 위한 컨트롤러를 만들면서, model로 전송할 내용들이 api와는 몇가지 달라진 점이 있는데,
모든 service, repository, domain, dto 코드들을 단 한 줄도 건드리지 않고 재활용하여 만들 수 있었다.
service 계층이 dto를 반환하고 있었다면, 컨트롤러 로직이 복잡해지거나 바꿀 코드들이 많았을 것 같다,
저번에 고민했던 dto의 생존 시점 고민이 도움이 됐던 것 같다.
도메인 생성을 제외한 나머지 로직은 dto가 컨트롤러까지만 살아있도록 구현했다.
사실 도메인 생성시에 필요한 값은 변할일이 많이 없으며, 변하더라도 서비스에 영향을 끼칠거라고 판단했다.
실제로 바꾼 컨트롤러에서도 생성 dto를 그냥 그대로 재활용했고,
나머지 경우엔 서비스가 dto가 아닌 엔티티만 반환하므로 컨트롤러에서 화면에 맞게 바꾸면 됐다.
로직이 Controller - Service 어디에 들어가는지 애매하다면
- 앱, 어드민 화면 등으로 화면 구현 바꿨을 때 다른 UI 코드랑 중복이 생기나?
- ui에 종속적인가, 핵심 비즈니스 로직인가?
를 생각해 보는 것이 좋을 것 같다.
화면을 변경해도 동일하게 나오는 로직이라면 서비스에 넣는 것도 나쁘지 않은 선택인 것 같다.
ui에 종속적인 화면이라면 Controller로, 핵심 비즈니스 로직이라면 service로 넣는 것이 좋은데
사실 핵심 비즈니스 로직이라는 것도 말이 애매하긴 한 것 같다.
모든 설계와 디자인 패턴에는 트레이드 오프가 존재하니까 상황에 맞춰서 잘 사용하는 것이 제일 좋아보인다.
3. Service의 의존관계
예재의 DevLogService는 3개의 Repository에 의존한다.
- 스케줄 선택을 위해 현재 존재하는 스케줄을 조회하는 ScheduleRepository
- 유저 선택을 위해 현재 존재하는 유저들을 조회하는 UserRepository
- 개발일지 저장, 조회 등의 로직을 담당하는 DevLogRepository
이렇게 하나의 서비스가 여러개의 리포지토리에 의존하면 서비스의 부담이 커지고,
코드 변경에 어려움이 있지 않을까 라는 생각을 했다.
하나의 서비스는 한 개의 리포지토리에만 의존하며 한 번에 하나의 비즈니스 로직만 수행하고,
컨트롤러에서 여러개의 서비스를 사용하는 것은 어떨까 싶었다.
- Controller - service 단일 상속 & service - repository 다중 상속
- 현재 방식, service가 모든 핵심 비즈니스 로직 처리
- 트랜잭션 원자성 준수
- 서비스가 repository에 너무 많이 의존함
- Controller - service 다중 상속 & service -repository 단일 상속
- 코드 변경에 좋음
- service가 단일 로직만 수행함, 변경에 용이, 버그 덜 생김
- controller 부담 커짐, 트랜잭션 원자성 어김
장 단점이 존재하지만 Controller 단에서 여러개의 service 코드를 호출할 경우,
트랜잭션 원자성이 깨진다는 큰 단점이 존재했다.
서비스 레이어 안에서 다시 계층을 나누는 Facade 패턴도 고민해봤는데,
현재 크기의 프로젝트에선 굳이 나눌 필요성을 못 느꼈고,
서비스 레이어를 쪼갤 경우 몇몇 서비스 레이어가 너무 가벼워질 것 같았다.
(리포지토리의 메소드를 그냥 불러오는 정도의 역할만 수행할 것 같았다.)
그래서 그냥 이대로 놔두기로 했다.
Controller를 새로 만드는데 전혀 이상이 없었으니까.
공부할수록 부족한 부분이 많이 보인다. 갈 길이 멀다.
근데 부족한게 잘 보이니까 가야할 길은 확실히 보이는 것 같다.
이제 mvc 2편을 들으면서 지금 만들어놨던 admin 페이지에 다른 기능들을 추가해봐야겠다.
'Spring > Spring MVC' 카테고리의 다른 글
| 사지방에서 Spring 공부하기 Web MVC #6 - 메세지 국제화 (5) | 2023.08.19 |
|---|---|
| 사지방에서 Spring 공부하기 Web MVC #5 - Thymeleaf 와 스프링 통합 (0) | 2023.08.19 |
| 사지방에서 Spring 공부하기 Web MVC #3 - 스프링 MVC 기본 기능 (0) | 2023.08.13 |
| 사지방에서 Spring 공부하기 Web MVC #2.5 - 스프링으로 로그 남기기 (0) | 2023.08.10 |
| 사지방에서 Spring 공부하기 Web MVC #2 - MVC 패턴과 프론트 컨트롤러 (0) | 2023.08.09 |