또 <> 제네릭스(Generics) 를 이용해 리스트에 들어갈 자료형을 선언해 줄 수 있다.
size() join() sort() 등의 함수도 사용할 수 있으나 사용법은 C++과 조금씩 차이가 있다.
Map
import java.util.HashMap;
public class Main {
public static void main(String[] args){
HashMap <String,String> myMap = new HashMap <> ();
myMap.put("key1","value1");
myMap.put("key2","value2");
System.out.println(myMap.get("key1")); // "value1"
System.out.println(myMap.containsKey("key2")); // true
System.out.println(myMap.keySet()); //[key1,key2]
System.out.println(myMap.remove("key2")); //value2
System.out.println(myMap.size()); // 1
}
}
HashMap을 통해 Map을 구현 가능하다.
C++ 의 map과 거의 동일하다.
put,get,remove를 통해 삽입,조회,삭제를 할 수 있다.
containsKey를 통해 키 유무를 확인할 수 있고 size를 통해 크기를 알 수 있다.
Set
package project;
import java.util.HashSet;
import java.util.Arrays;
public class Main {
public static void main(String[] args){
HashSet <String> mySet1 = new HashSet <> (Arrays.asList("1","2","3"));
HashSet <String> mySet2 = new HashSet <> (Arrays.asList("3","4","5"));
System.out.println(mySet1); // [1,2,3]
mySet1.retainAll(mySet2); // 교집합
System.out.println(mySet1); // [3]
mySet1.addAll(mySet2); // 합집합
System.out.println(mySet1); // [3,4,5]
mySet1.removeAll(mySet2); // 여집합
System.out.println(mySet1); // []
}
}
HashSet를 통해 Set를 구현이 가능하다.
retailAll,addAll,removeAll을 통해 교집합,합집합,여집합 연산을 수행할 수 있다.
제어문 (if , if else, else, for, while, switch 등등)
제어문 구조는 c와 그냥 일치한다.
c 문법대로 그대로 사용하면 될 듯 하다.
2. Class
생성
package project;
class Animal {
int legs = 4;
}
class Cat extends Animal {
int getLegs(){
return this.legs;
}
}
class Dog extends Animal {
String name;
Dog(String name){
this.name = name;
}
int getLegs(){
return this.legs;
}
String getName(){
return this.name;
}
}
public class Main {
public static void main(String[] args){
Dog dog = new Dog("puppy"); // 클래스 생성
Animal cat = new Cat(); // 업캐스팅
//Dog animal = new Animal(); // 에러! 다운캐스팅은 불가능!!
// System.out.println(cat.getLegs()); //에러!
System.out.println(dog.getLegs()); // 4
System.out.println(dog.getName()); // puppy
}
}
객체 생성 방법은 C++에서 new를 이용해 동적으로 객체를 생성하는 방법과 동일하다.
상속 키워드는 extends 이며 C++과 다르게 다중 상속은 지원하지 않는다.
메소드 오버라이딩 오버로딩 모두 가능하며 업캐스팅 생성은 가능하지만 다운캐스팅은 불가능하다.
class BaseSerializer(serializers.ModelSerializer):
class Meta:
model = Base
fields = ('name','alcohol_degree')
class CocktailBaseSerializer(serializers.ModelSerializer):
alcohol_degree = serializers.SerializerMethodField(read_only = True)
class Meta:
model = CocktailBase
fields = ('name','amount','alcohol_degree')
def get_alcohol_degree(self,obj):
return obj.name.alcohol_degree
class CocktailSerializer(serializers.ModelSerializer):
glass = serializers.StringRelatedField(read_only = True)
base = CocktailBaseSerializer(many = True,read_only = True, source ='cocktail_base')
sub = CocktailSubSerializer(many = True, read_only = True, source = 'cocktail_sub')
juice = CocktailJuiceSerializer(many = True,read_only = True, source = 'cocktail_juice')
other = CocktailOtherSerializer(many = True,read_only = True, source ='cocktail_other')
class Meta:
model = Cocktail
fields = ('name','base','sub','juice','other','recipe','img_url','glass')
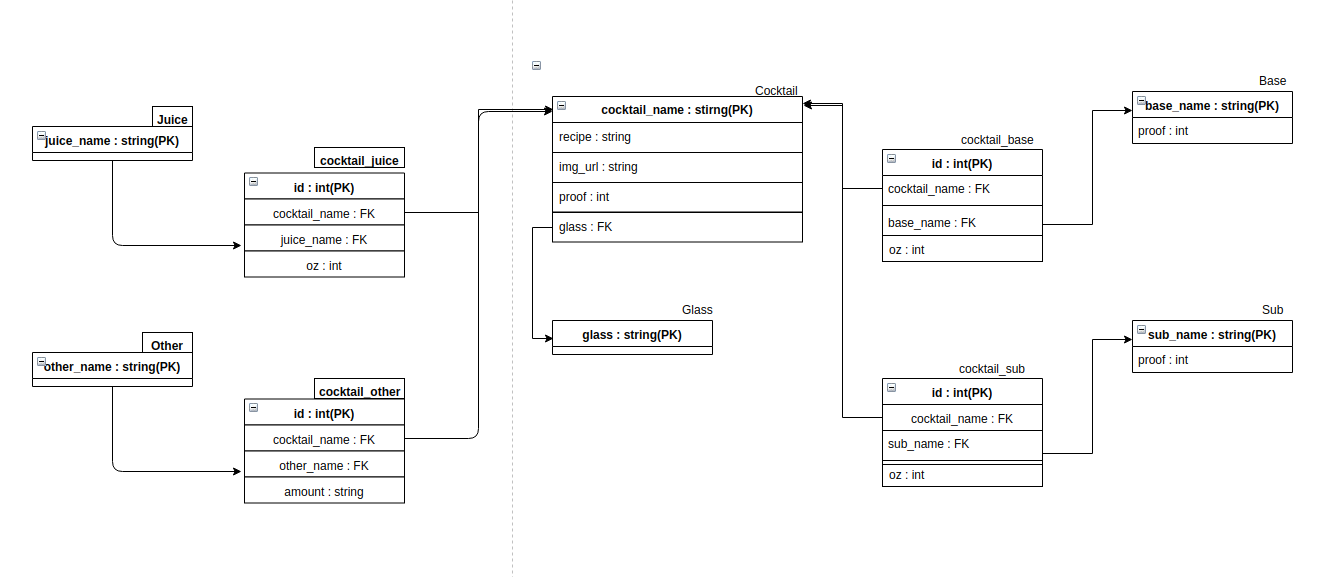
다음과 같은 방식으로 serializer를 구현했다.
DRF는 ManyToManyField를 직렬화하는 serializer를 구현할때
대부분 읽기 전용으로만 구현이 가능하고 생성시엔 create함수를 오버라이딩 하거나 views에서 직접 모델을 건드려야 한다.
그래서 나는 후자 방식을 선택했다.
CocktailSerializer의 필드를 보면 대부분 필드에 read_only = True로 설정되어 있는 것을 볼 수 있다.
그리고 읽을 때는 마찬가지로 중간 테이블의 정보를 같이 읽어야 하므로 CocktailBaseSerializer을 같이 만들어야 한다.
(이 방식 외에도 다른 방식이 있는데 DRF 공식 문서의 NestedSerializer 부분을 읽고 오는 것을 추천한다.)
가장 중요한 것은 source = 'cocktail_base'(중간 테이블 모델의 related_name 부분) 를 입력해주지 않으면
Serializer가 자동으로 중간테이블을 건너 뛰고 바로 Base 모델을 가져온다.
3) views.py
from django.shortcuts import render, get_object_or_404
from django.http import HttpResponse, JsonResponse
from django.views.decorators.csrf import csrf_exempt
from rest_framework.parsers import JSONParser
from .models import *
from .serializers import *
def check_cocktail_data(model,query_set): #유효성 검사 함수 - 재료가 존재하는지 확인
for data in query_set:
if not model.objects.filter(name = data['name']).exists():
return False
return True
# 중간 테이블에 칵테일과 재료 연결하는 함수
def create_mapping_table(mapping_table_model,query_set,cocktail,ingredient_model):
for data in query_set:
name = ingredient_model.objects.get(name = data['name'])
mapping_table_model.objects.create(cocktail = cocktail, name = name, amount = data['amount'])
@csrf_exempt
def cocktails(request):
if request.method == 'GET': # 칵테일 레시피 전체 요청
cocktails = Cocktail.objects.all()
serializer = CocktailSerializer(cocktails, many=True)
return JsonResponse(serializer.data,safe = False)
elif request.method == 'POST': # 칵테일 레시피 등록
data = JSONParser().parse(request)
base_data = data.pop('base') #외래키 등록 필요한 항목들
sub_data = data.pop('sub')
juice_data = data.pop('juice')
other_data = data.pop('other')
glass_data = data.pop('glass')
serializer = CocktailSerializer(data = data)
# ---유효성 검사---
if (serializer.is_valid()
and Glass.objects.filter(name = glass_data).exists()
and check_cocktail_data(Base,base_data)
and check_cocktail_data(Sub,sub_data)
and check_cocktail_data(Juice,juice_data)
and check_cocktail_data(Other,other_data)):
# --- 유효성 검사 통과 ---
cocktail = serializer.save()
glass = get_object_or_404(Glass, name = glass_data) #Glass 연결
cocktail.glass = glass
# --- 중간 테이블 연결 ---
create_mapping_table(CocktailBase,base_data,cocktail,Base)
create_mapping_table(CocktailSub,sub_data,cocktail,Sub)
create_mapping_table(CocktailJuice,juice_data,cocktail,Juice)
create_mapping_table(CocktailOther,other_data,cocktail,Other)
cocktail.save()
return JsonResponse(serializer.data, status=status.HTTP_201_CREATED)
# error_data = {"error_code":400, "error_message":f"invalid data"}
return JsonResponse(serializer.errors, status = 400)
ManyToManyField 연결 을 views.py에서 진행했다.
POST method와 함께 request body로 데이터가 들어오면 올바른 데이터인지 유효성 검사를 진행한 후
외래키 테이블을 제외한 정보들(칵테일 이름, 조합법, 이미지 등)은 serializer을 통해 만들고
create_mapping_table함수를 통해 중간 테이블을 하나씩 연결해주는 방식이다.
5. 마무리하며
사실 일주일이라는 시간동안 리팩토링을 진행했는데 5일 정도는 시간을 날리기만 하고 진짜 개발은 마지막 2일에 다 한 것 같다.
평일에 컴퓨터를 할 수 있는 시간이 적어서 그런것도 같지만 그냥 api 명세를 제대로 안 짜고 맘대로 만들다가
이게 더 좋을 거 같은데..? 하고 다시 만들고.. 만들다가 막혀서 검색해봤더니 더 좋은 방식이 생각나서 또 갈아엎고..
이 과정을 반복하는데 5일을 썼다.
물론 그 과정에서 잊어버렸던 python 문법과 django, git, 노션 사용법, 에 관해서 다시 기억해낼 수 있는 시간이었다.
이때 그냥 구글 아이디로 로그인을 하면 컴퓨터를 끄면 모든 내용이 초기화되는 사지방 특성상
매번 로그인 할 때마다핸드폰으로 Gmail을 키고 2차 인증을 해야하므로
이메일 인증을 하고 아이디를 새로 만드는 것을 추천한다.
컨테이너 생성시엔 장고를 이용해 개발을 한다고 소프트웨어 스택에서 냅다 장고를 고르지말고
파이썬으로 고르는 것을 추천한다.
장고를 고르고 했더니 알아서 장고 프로젝트를 만들어 주는건 좋은데
DRF를 이용해 백엔드 API를 만드려면 어차피 그 프로젝트 삭제하고 다시 만들어야한다.
프로젝트 이름 등은 알아서 설정하고
그 외에는 그냥 mysql 또는 mongoDB설치 정도만 설정하고 나머진 그냥 진행하면 될 것 같다.
2. 가상환경 설정 및 프레임워크 설치
소프트웨어 스택을 파이썬으로 설정했다면 파이썬3가 설치되어있는 ubuntu 기반의 서버를 사용할 수 있다.
root@goorm: /woorkspace/폴더 밑에 아까 설정한 프로젝트 이름으로 파일들이 생성된다.
mkdir venvs # 가상환경용 파일 생성
cd venvs # 만든 파일 진입
python -m venv cocktail # cocktail 이라는 이름으로 가상환경 생성
이후 만들어진 파일로 들어가 가상환경을 실행시키고 장고 및 필요한 프레임워크들을 다운 받으면 된다.
(django,django-rest-framework,mysqlclient,corsheaders 등을 설치했다.)
cd cocktail/bin
source activate #가상환경 실행
컨테이너 생성시에 mysql 설치 항목에 체크를 했다면 mysql은 이미 설치된 상태이다.
3. 깃허브 연동 및 프로젝트 파일 생성
장고 프로젝트 생성은 원래 "django-admin startproject" 명령어를 통해 진행하지만
기존에 만들던 백엔드 API를 수정하는 것이 목표이므로 깃허브에 미리 올려뒀던 파일을 clone 해오는걸로 대체했다.
왼쪽 탭의 GIT 메뉴를 누르고 저장소 연결하기를 통해 clone을 해도 되고
터미널에서 git clone "http:// ...." 명령어를 통해 clone을 해와도 된다.
4. DB연동 (MySQL)
mysql 설치를 이미 해놨기 때문에 장고 프로젝트에 연결만 하면 된다.
sudo service mysql start # mysql 시작
sudo mysql -u root -p #root 계정으로 mysql 진입 비밀번호는 아무거나 치면 됨
use mysql;
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '원하는 비밀번호';
mysql이 제대로 설치됐는지 확인해본 후 루트 계정의 비밀번호를 바꿔준다. (phpmyadmin 사용을 위해)