2편에서 튜링 머신과 튜링 완전한 프로그래밍 언어에 대해 설명했다.
이제 직접 튜링 완전한 프로그래밍 언어를 만들어보자.
교수님 습관으로 프로그래밍 언어 만들기
내가 만들 프로그래밍 언어는 사실 우리과 교수님의 말버릇이다.
이왕 만드는 거 재밌게 만드는게 좋으니까, 평소에 좋아하는 교수님의 말버릇을 주제로 만들어봤다.
(이런 글을 써도 되는지 모르겠지만, 혹시 문제가 되면 바로 지우겠습니다. 죄송합니다 교수님)
교수님의 평소 강의 말버릇이 조금 독특하신데,
영어 강의를 진행하실 때 명사 앞에 the 와 a를 거의 매번 같이 붙이신다.
그래서 듣다보면 디어,,, 디어,,,가 반복되는데, 어느새 우리 과 컴공 사람들은 대부분 아는 교수님의 시그니처가 됐다.
(다시 한 번 말하지만 교수님을 희화하하려는 것이 아닙니다... 저는 교수님 수업 정말 재밌게 잘 들었습니다. 교수님 사랑해요)
그리고 수업 중간 중간에 '이런건 앞으로 여러분들 인생에 아무짝에도 쓸모없는거죠' 라고 하면서 자주 설명을 해주신다.
근데 그렇게 말씀하셔놓고 설명도 자세하게 해주시고, 내용도 흥미로워서 재밌게 들었는데 이것도 넣어봤다.
언어의 구조는 2편에서 설명한 BrainFu**과 동일하게 만들었다.
| 디 | 포인터 증가 |
| 디이 | 포인터 감소 |
| . | 포인터가 가리키는 값 1 증가 |
| , | 포인터가 가리키는 값 1 감소 |
| 어 | 포인터에 저장된 값 ASCII 코드로 출력 |
| 어어 | 키보드로 값을 입력 받아 포인터에 저장 |
| 앞으로인생에있어서 | 반복문 시작 |
| 아무쓸모도없는거죠 | 반복문 종료(포인터 값이 0이 아니면 시작으로 이동) |
재미를 위해서 코드의 시작과 끝에는 교수님의 시작과 끝 멘트인
'헬로에브리원투데이이즈' 와 ''오늘은여기까지하겠습니다' 를 넣어야 하도록 해봤다.
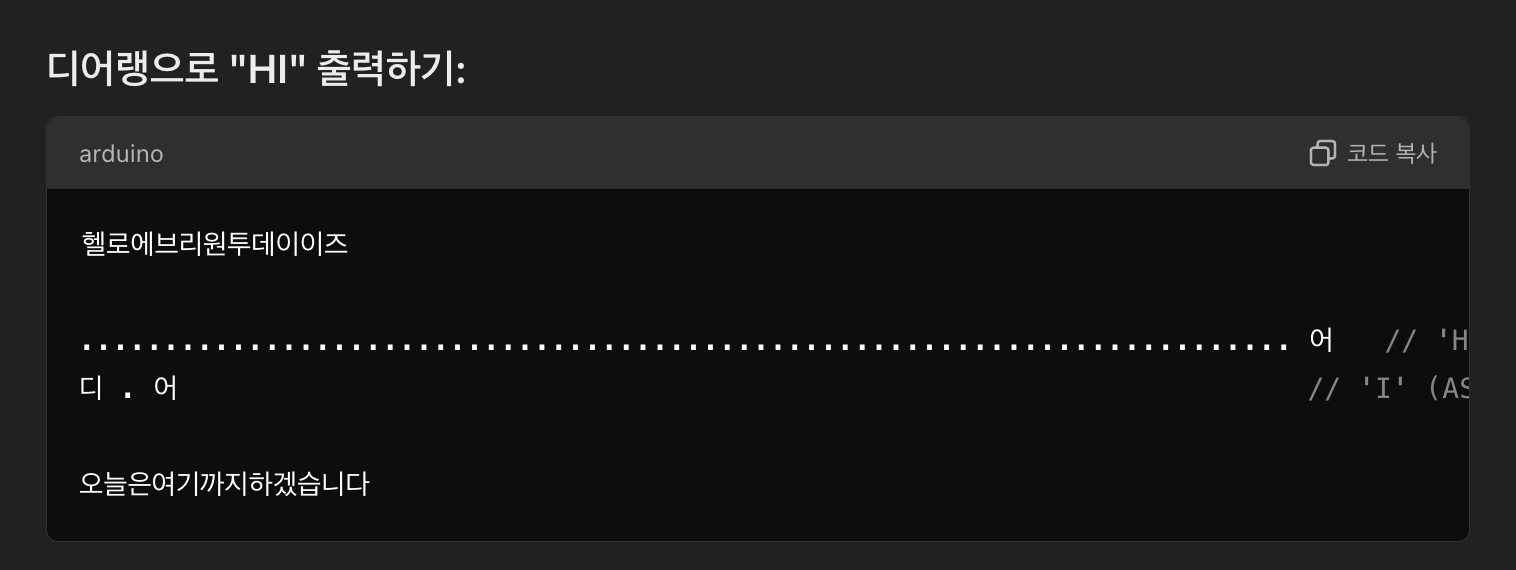
이제 이 언어로 HELLO WORLD를 출력해보자
헬로에브리원투데이이즈
디..... ..
앞으로인생에있어서
디..... .....
디..... .....
디..... .....
디..... .....
디이 디이 디이 디이,
아무쓸모도없는거죠
디.. 어
디, 어
디..... .어
어
디..... ....어
디...
앞으로인생에있어서
디..... .....
디이,
아무쓸모도없는거죠
디...어
디..... .....
앞으로인생에있어서
디..... ....
디..... ...
디..... ...
디..... ...
디..... ..
디이 디이 디이 디이 디이,
아무쓸모도없는거죠
디,,,어
디, 어
디..어
디,,,,어
디,,어
오늘은여기까지하겠습니다컴파일러 동작 과정 알아보기
[컴파일러] 토크나이저, 렉서, 파서 (Tokenizer, Lexer, Parser)
컴파일러 [컴파일러] 컴파일러란? 컴파일러 컴파일러는 명령어 번역 프로그램이다. 컴파일러는 소스 코드 혹은 원시 코드를 목적 코드로 옮겨주는 역할을 한다. 쉽게 설명하면 여기서 소스 코드
gobae.tistory.com
아직 프로그래밍 언어나 컴파일러에 대한 수업을 들어보질 않아서, 네이버 블로그를 참고했다.
프로그래밍 언어가 기계화로 바뀌는 과정은 구문 분석, 최적화, 코드 생성, 링킹의 과정을 거친다고 한다.
그러나 우리는 실제 기계어로 변환해주는 컴파일러를 구현하지는 않을 거고, 여러 파일을 합쳐 실행파일을 만드는 기능도 필요없다.
(어차피못만든다)
최적화도 할 필요가 없다. 최적화가 필요하면 이런걸 쓰겠냐
그래서 구문 분석후 실행의 역할만 하면 된다.
그래서 컴파일러의 Tokenizer, Lexar, Parser를 이용한 구문 분석 과정을 조금 참고해서 구현해봤다.
Tokenizer은 코드를 최소한의 의미를 가지는 '토큰'으로 쪼개는 역할을 한다.
또한 이 과정에서 필요 없는 문자(공백, 주석) 등을 제거한다.
Lexar는 Tokenizer에 의해 쪼개진 토큰의 의미를 분석한다. (해당 토큰에 의미를 부여한다)
Parser는 의미가 부여된 토큰들을 계층 구조로 나타낸다.
해당 과정을 모두 거치고 나면 분석된 구문은 트리 형태로 정렬 된다.
이렇게 구문을 분석해 만든 트리를 AST(Abstract Syntax Tree)라고 한다.
Tokenizer 구현하기
class Compiler():
def compile(self,filename):
...
def tokenize(self, file):
lines = file.readlines()
tokens = []
#split every lines by blank
for line in lines:
words = line.strip().split() #remove \n
if words == []: continue #skip empty line
for word in words:
start = 0
now = 0
while now < len(word):
if word[now] == '디':
if not start == now:
tokens.append(word[start:now])
if now+1 < len(word) and word[now+1] == '이':
tokens.append(word[now:now+2])
now += 2
start = now
else:
tokens.append(word[now])
now += 1
start = now
elif word[now] == '어':
if not start == now:
tokens.append(word[start:now])
if now+1 < len(word) and word[now+1] == '어':
tokens.append(word[now:now+2])
now += 2
start = now
else:
tokens.append(word[now])
now += 1
start = now
elif word[now] == '앞' or word[now] == '아':
if not start == now:
tokens.append(word[start:now])
tokens.append(word[now:now+9])
now += 9
start = now
else:
now += 1
if not start == now:
tokens.append(word[start:now])
return tokens
우리 코드의 Token은 각각의 명령어들이다.
Compilier 클래스를 만들고 tokenize라는 메서드 함수를 만들어 구현했다.
우리 프로그래밍 언어에서 공백은 필요가 없기에 공백을 모두 제거하고, 명령어 단위로 묶어서 토큰을 만들었다.
그리고 보통 포인터 값 증가/감소 명령어인 . , 는 붙여서 많이 쓰이기 때문에 붙여서 토큰으로 인식해도 무방할 것 같아 그렇게 진행했다.
위의 예시의 HELLO WORLD 코드를 토큰으로 분해하면 다음과 같다.
['헬로에브리원투데이이즈',
'디', '.....', '..',
'앞으로인생에있어서',
'디', '.....', '.....',
'디', '.....', '.....',
'디', '.....', '.....',
'디', '.....', '.....',
'디이', '디이', '디이', '디이', ',',
'아무쓸모도없는거죠',
'디', '..', '어', '디', ',', '어',
'디', '.....', '.', '어', '어',
'디', '.....', '....', '어',
'디', '...',
'앞으로인생에있어서',
'디', '.....', '.....', '디이', ',',
'아무쓸모도없는거죠',
'디', '..', '어',
'디', '.....', '.....',
'앞으로인생에있어서',
'디', '.....', '....',
'디', '.....', '...',
'디', '.....', '...',
'디', '.....', '...',
'디', '.....', '..',
'디이', '디이', '디이', '디이', '디이', ',',
'아무쓸모도없는거죠',
'디', ',,,', '어',
'디', ',', '어',
'디', '..', '어',
'디', ',,,,', '어',
'디', ',,', '어',
'오늘은여기까지하겠습니다']
AST 구현없이 실행시키기
사실 여기서 의미를 부여하고 계층 구조를 만드는게 필요한가 싶었다.
토큰 자체가 하나하나 매우 간단한 명령어이고, 계층 구조를 만들 필요가 있는 건 반복문 뿐인데
계층 구조를 만드는거보다, 그냥 스택에다가 분기 명령어 위치 저장해놓고 쓰는게 더 편할 것 같았다.
def excute(self, tokens):
tape = [0]
pointer = 0
stack = []
#checking syntax
if not(tokens[0] == '헬로에브리원투데이이즈' and tokens[-1] == '오늘은여기까지하겠습니다'):
print("Syntax Error!")
exit(0)
# for i in range(1, len(tokens)-1, 1):
i = 1
while i < (len(tokens) - 1):
if tokens[i] == '디':
pointer += 1
if pointer >= len(tape):
tape.append(0)
elif tokens[i] == '디이':
pointer -= 1
if pointer < 0:
print("pointer underflow error!")
exit(0)
elif tokens[i] == '어':
# print(tape, pointer)
print(chr(tape[pointer]), end="")
elif tokens[i] == '어어':
tape[pointer] = int(input())
elif tokens[i] == '앞으로인생에있어서':
if tape[pointer] == 0:
while not tokens[i] == '아무쓸모도없는거죠' and i < len(tokens):
i += 1
else:
stack.append(i)
elif tokens[i] == '아무쓸모도없는거죠':
if tape[pointer] == 0:
stack.pop()
else:
i = stack[-1]
else:
number = 0
for char in tokens[i]:
if char == '.':
number += 1
else:
number -= 1
tape[pointer] += number
i += 1
print('\0')
다시봐도 정말 쓰레기 같은 하드 코딩이다.
하지만 이걸 열심히 해봤자, 아무 도움이 안된다는 걸 알기에
심심풀이용으로 대충 만들어봤다.
실행 결과

잘 나온다
ㅋㅋㅋㅋㅋㅋㅋ
구현하면서 신기했던건, 문법이 간단하고 한 번 구조를 잘 만들어놓으니까 정말 프로그래밍 언어처럼 잘 동작한다.
중간에 다른거도 출력해보려고 코드를 바꿔봤는데 결과가 잘 안나와서,
내가 컴파일러 구현에 실수한게 있었나 하고 봤는데 알고보니까 코드에 띄어쓰기 오류가 있었다.
이 정도면 진짜 프로그래밍 언어가 아닐까?
물론 이걸 컴파일러라고 부르기엔 애매하고, 인터프리터라고 하는 게 더 알맞은 표현 아닐까 싶지만 이 정도는 그냥 넘어가자.

챗 지피티한테도 알려줬는데 잘 못한다.
너무 어려운걸 시켰나보다.
마무리하며
사실 시험기간에 그냥 심심해서 떠올린 아이디어가 생각보다 공부할게 많은 주제였던것 같다.
그리고 오토마타에서 추상적으로 다루기만 했던 내용들을 실제로는 이런거 만들때도 쓰이는구나 라는 것도 배울 수 있었다.
용두사미처럼 끝난 거 같은데 많은 분들이 재밌어 해주셨으면 좋겠다.
아 그리고 교수님 제가 많이 존경합니다.
이번학기 수업 재밌게 잘 들었습니다.
문제가 되면 지우겠습니다.
'전공 공부' 카테고리의 다른 글
| 오토마타 배워서 어디에 써먹나요? - 2. 튜링 머신과 튜링 완전 (0) | 2024.12.19 |
|---|---|
| 오토마타 배워서 어디에 써먹나요? - 1. 오토마타란? (2) | 2024.12.19 |